※配布用ではなく、Radeon 520 の GPU 処理能力を Python 側から検証するための 小規模な試作・検証(Proof of Concept)です。
概要
開発が目的ではなく、新しいハードウェアハックの知識を漁っていました。GPUでPythonを加速させる「Taichi」という面白そうな道具を見つけ、手元の「使いづらいRadeon 520」で何ができるか試してみたくなりました。Vulkan環境が整っていたこと、LLMという強力な壁打ち相手がいたことで実現することができました。これらを繋ぎ合わせたら、2〜3時間かからずにBlenderのアニメーション処理をGPUに肩代わりさせるアドオンができました。
ハックの結果
コードの中身はLLMに丸投げしました。プロンプトも経路が複雑(関係のない話の連続)で再現不能ですが、「計算資源としてGPUを再定義する」という実験は成功しました。同じアニメーションを繰り返し再生させて、動きを確認する際に役に立つアドオンができました。
環境
- blender4.1
- Windows11
- Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz 1.99 GHz
- AMD Radeon 520 2GB GDDR5 vRAM
- RAM DDR4 32GB
- NVME Gen3
経緯
Blender 4.1ではRadeon 520などの古いGPUを初期設定ではうまく活用できませんでした。ある時、GPUでPython演算を高速化できる「Taichi」という存在を知り、Blenderで使えそうだなと思いつきました。
実装内容
pip install taichiを実行して、環境にTaichiをインストールします。- PythonでTaichiのコードを記述して〇〇.pyで保存します。
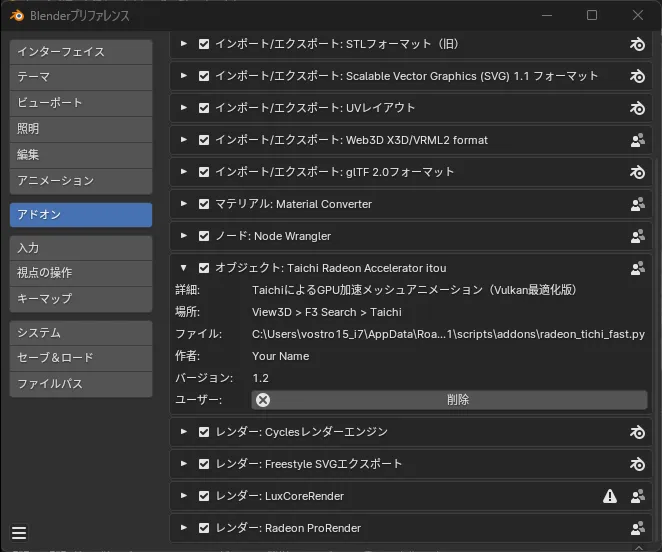
- blenderを開きプリファレンスでアドオン項目から作成した〇〇.pyを読み込みます。
- 読み込ませた〇〇.pyファイルを探して✅を入れます。
※〇〇.pyは各自好きな名前で保存してください。
アドオンコード
通常のアドオンと同じ手順で〇〇.pyファイルをインストールして有効化 すれば、そのまま使用できます。
# SPDX-License-Identifier: GPL-3.0-only
# (C) 2026 itou332
import bpy
import taichi as ti
import numpy as np
from bpy.app.handlers import persistent
bl_info = {
"name": "Taichi Radeon Accelerator",
"author": "itou332",
"version": (1, 2),
"blender": (4, 1, 0),
"location": "View3D > F3 Search > Taichi",
"description": "TaichiによるGPU加速メッシュアニメーション(Vulkan最適化版)アドオンの説明(blender4.1以外は未確認)",
"category": "Object",
}
# --- 1. Taichiの初期化 ---
if not ti.lang.impl.get_runtime().prog:
# Radeon向けにVulkanを指定。NVIDIAならti.cudaも可
ti.init(arch=ti.vulkan)
# --- 2. GPU計算カーネル ---
@ti.kernel
def compute_wave(verts: ti.types.ndarray(), t: ti.f32):
# ここの並列処理が「とんでもない速さ」の正体
for i in range(verts.shape):
x = verts[i, 0]
y = verts[i, 1]
# GPU負荷を上げ、Radeonを本気で働かせるための多重波合成
val = 0.0
for n in range(1, 6):
val += ti.sin(x * n * 2.5 + t) * (0.2 / n)
val += ti.cos(y * n * 1.8 + t * 0.7) * (0.15 / n)
verts[i, 2] = val
# --- 3. ハンドラーと処理の実体 ---
_cached_verts = None
def frame_handler(scene):
global _cached_verts
obj = bpy.context.active_object
if not obj or obj.type != 'MESH':
return
mesh = obj.data
v_count = len(mesh.vertices)
# 毎フレームのメモリ確保を避け、CPUのオーバーヘッドを極限まで削る
if _cached_verts is None or _cached_verts.shape != (v_count * 3,):
_cached_verts = np.zeros(v_count * 3, dtype=np.float32)
# Blenderからデータを取得
mesh.vertices.foreach_get("co", _cached_verts)
# 配列を整えてGPUへ転送(コピーなしのビュー参照)
reshaped_verts = _cached_verts.reshape((-1, 3))
# GPU計算実行
compute_wave(reshaped_verts, scene.frame_current * 0.1)
# 結果をBlenderのメッシュに書き戻す
mesh.vertices.foreach_set("co", _cached_verts)
mesh.update()
@persistent
def load_handler(dummy):
"""ファイルを開いたときに自動で計算を有効化"""
if frame_handler not in bpy.app.handlers.frame_change_pre:
bpy.app.handlers.frame_change_pre.append(frame_handler)
def warmup_taichi():
"""アドオン有効化時にダミー計算を行い、JITコンパイルを先に済ませる"""
dummy_verts = np.zeros((1, 3), dtype=np.float32)
compute_wave(dummy_verts, 0.0)
print("Taichi: Warmup complete. High-speed mode enabled.")
# --- 4. オペレーター ---
class TAICHI_OT_Start(bpy.types.Operator):
bl_idname = "object.taichi_start"
bl_label = "Taichi加速開始"
def execute(self, context):
if frame_handler not in bpy.app.handlers.frame_change_pre:
bpy.app.handlers.frame_change_pre.append(frame_handler)
self.report({'INFO'}, "Taichi加速: ON")
return {'FINISHED'}
class TAICHI_OT_Stop(bpy.types.Operator):
bl_idname = "object.taichi_stop"
bl_label = "Taichi停止"
def execute(self, context):
if frame_handler in bpy.app.handlers.frame_change_pre:
bpy.app.handlers.frame_change_pre.remove(frame_handler)
self.report({'INFO'}, "Taichi加速: OFF")
return {'FINISHED'}
# --- 5. 登録と解除 ---
classes = (TAICHI_OT_Start, TAICHI_OT_Stop)
def register():
for cls in classes:
bpy.utils.register_class(cls)
# 起動時の「から回し」
try:
warmup_taichi()
except:
pass
if load_handler not in bpy.app.handlers.load_post:
bpy.app.handlers.load_post.append(load_handler)
print("Taichi Radeon Accelerator itou: Registered")
def unregister():
# 安全なクラス解除
for cls in reversed(classes):
if hasattr(cls, "bl_rna"):
try:
bpy.utils.unregister_class(cls)
except RuntimeError:
pass
if load_handler in bpy.app.handlers.load_post:
bpy.app.handlers.load_post.remove(load_handler)
if frame_handler in bpy.app.handlers.frame_change_pre:
bpy.app.handlers.frame_change_pre.remove(frame_handler)
print("Taichi Radeon Accelerator: Unregistered")
if __name__ == "__main__":
register()
以上で設定完了です。
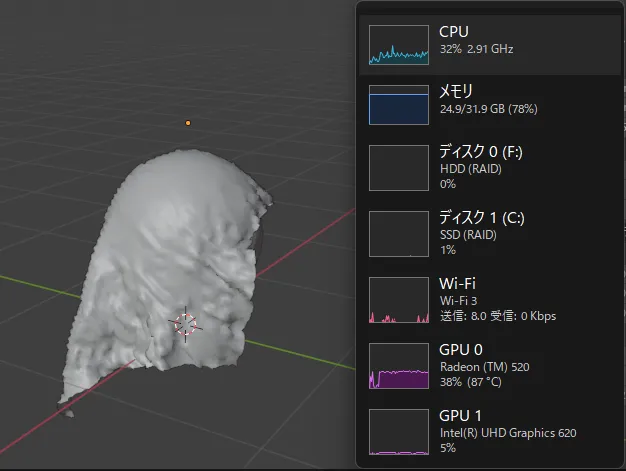
動作確認はWindows11のタスクマネジャーでGPU項目を眺めながら確認します。meshをアニメーションさせた時のGPUの挙動を目視で確認します。
※注意点
「一度目のアニメーション実行はこれまでと同じ速度です。(アドオンを入れる前と同じ)2回目以降のアニメーションはGPUを使って高速に快適に動きます。Taichiがgpu専用の回路を構築(コンパイル)するまで時間がかかります。 準備が整えば、GPUを活用した高速メッシュアニメーションの再生が実行可能になります。」
結論
古いGPUを有効活用するために開発したアドオンですが、その真価は高性能な計算機でこそ発揮されます。メッシュアニメーションの初動の演算開始速度はCPU性能に左右されます。そこを力押しできる高性能な環境こそが、本アドオンの性能を余すことなく享受できる最適な構成です。
感想
使いづらいRadeonを使っていたことと、Taichiを知ったことをきっかけに、古いGPUでも計算資源として活用できることがわかりました。個人的には新しいことを発見できて面白かったです。